If you read any of the SECRET papers, it is not a SECRET for you that using Machine Learning (ML) to detect malware is a challenging endeavor. In one of these papers, we presented the results of our participation in a machine learning-based malware detection evasion challenge dating back 2019. It happens that another edition of the challenge has gone in this crazy 2020 and we found it even more interesting. While we don’t report our findings in a scientific venue, we share our first impressions and thoughts here in this blog post.
But before digging into the 2020’s challenge, let’s remind you of some things about the 2019 challenge.
The 2019 Challenge
It was another random day reading random tweets when something got our attention: a challenge to modify real malware samples to bypass machine learning (ML)-based malware detectors. Such an invitation for malware researchers, hun? Formally, it was the Machine Learning Security Evasion Competition (MLSEC) launched by Elastic, Endgame, MRG-Effitas, and VM-Ray companies at DEFCON’s AIVillage to promote ML-based malware detections. In turn, in our mind, it was something like:

Back to the challenge rules, they were somehow straightforward: the organizers provided participants with 50 working malware binaries and 3 malware classifiers (white box model, no restrictions on the number of queries performed locally) that initially detected all these malware samples. These very same binaries needed to be modified by the participants in order to bypass their detection in the classifiers, whereas still presenting the same original behavior when executed in a sandbox, i.e., resulting in the same Indicators of Compromise (IoCs) of the original ones. The winner was the one who first achieved more points (150 in total).
We did not win this challenge (we were the second to bypass all models thus we got 2nd place), but we learned many tricks that we used in the 2020’s edition, so we think they worth a mention. In a general way, we learned that string-based models can be bypassed by appending strings retrieved from goodware binaries. If you add strings enough, the classification goes towards the goodware class. This method is really interesting because you can append random data at the end of an executable file without affecting its behavior. A single shell >> to bypass many classifiers!
For the models using PE features, well, changing the binary is the way to get there, but it is hard and boring. So let’s be lazy as usual and adopt a more straight-to-the-point approach: let’s hide the original binary within a new binary (a dropper). This way, we don’t need to write anything on the original malware sample, we just code our own malware. That’s what we did, and things went pretty well, all models bypassed. A pity we discovered it a bit late!
Anyway, we made our dropper available on github. Of notice, it was already prepared for future evolutions, such as adding XOR “encryption”, as reverting some commits shows:
| for(int i=0;i<size;i++){ | |
| // byte pointer | |
| unsigned char c1 = ((char*)data)[i]; | |
| // add your encryption/decryption routine here | |
| // drop byte to file | |
| fprintf(f,"%c",c1); | |
| } | |
| // file fully written | |
| fclose(f); |
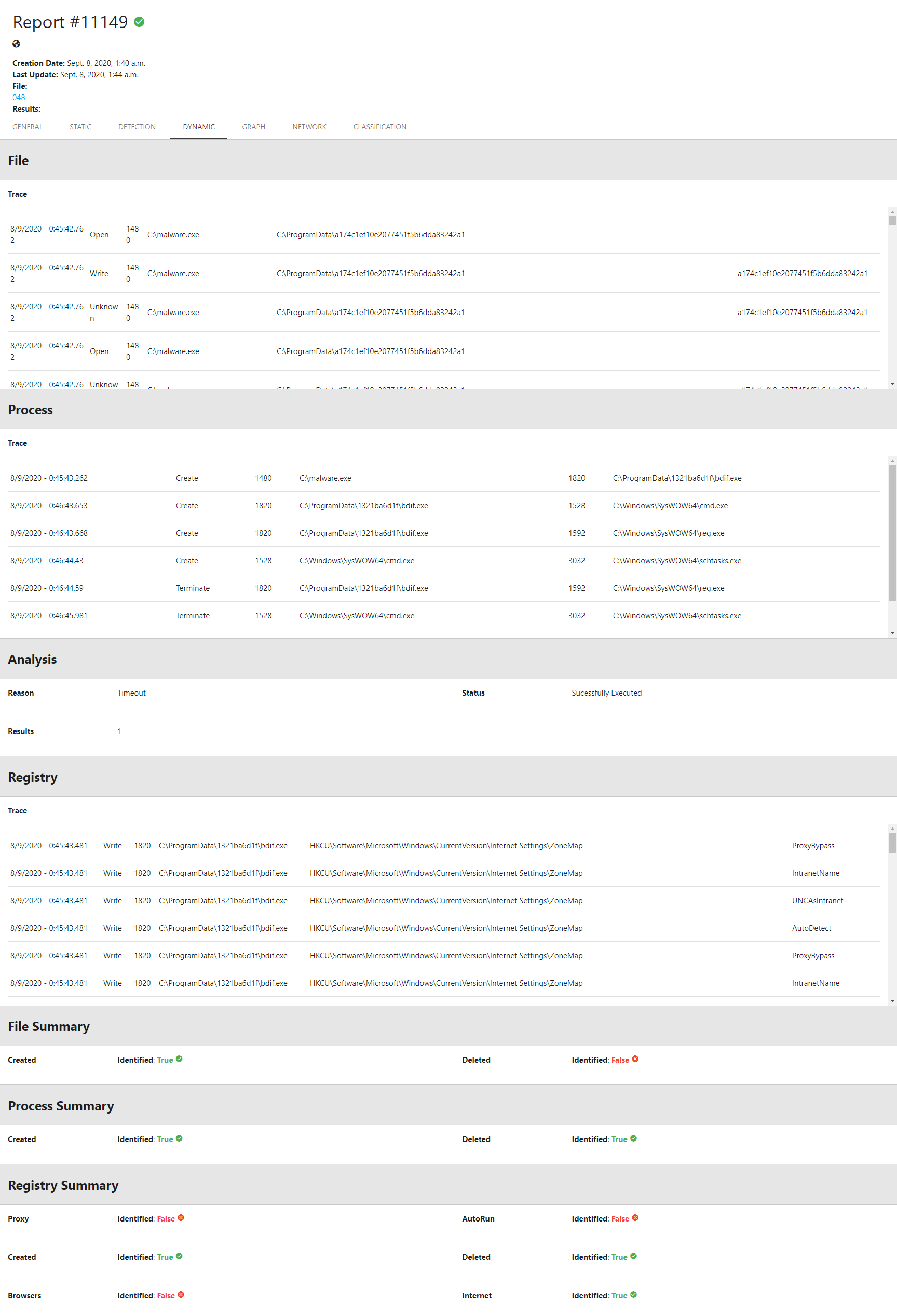
We don’t know how prepared for the challenge the other competitors were. Fortunately, we are lucky and had a malware analysis infrastructure prepared to help us. Thus, we did not need to submit a sample to the challenge sandbox to discover if the modifications worked. We submitted the samples to our own sandbox and checked everything locally. This allowed us to submit to the challenge only already-tested samples (this will be important in 2020).
Example of dynamic traces captured by Corvus.
Later, we integrated all the challenge’s models in our sandbox, so we could test any sample against them at any time (and this will be important again for 2020), as shown in Figure below.
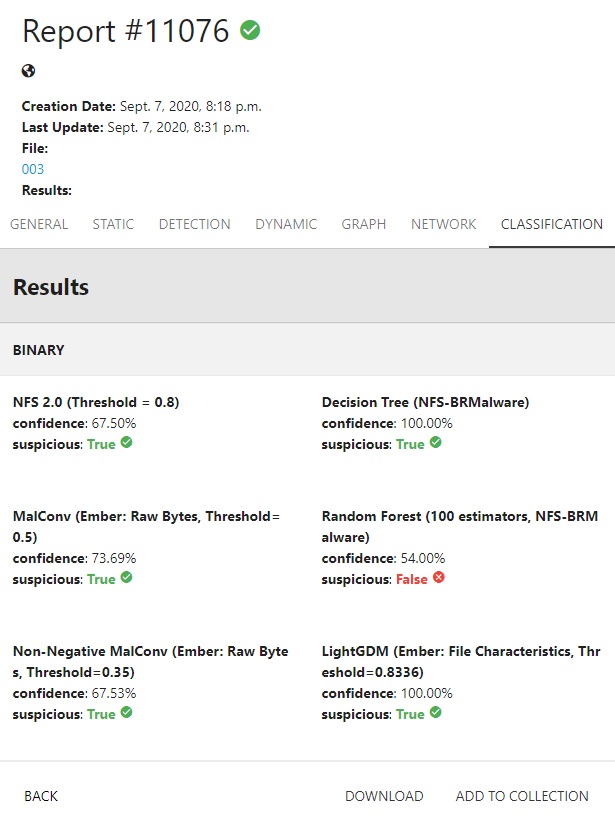
ML report from sample 003 of MLSEC 2020.
Interestingly, the 2019’s experience also allowed us to understand some countermeasures against these types of evasion. The most interesting one is that the samples become more similar when you embed them in the same shell and append to them the same strings. This would allow similarity-based approaches to detect these files as similar. In fact, we presented this effect during our ROOTS’19 presentation. To help anyone to identify this type of similar construction, we also added this feature to our sandbox, as you can see here:
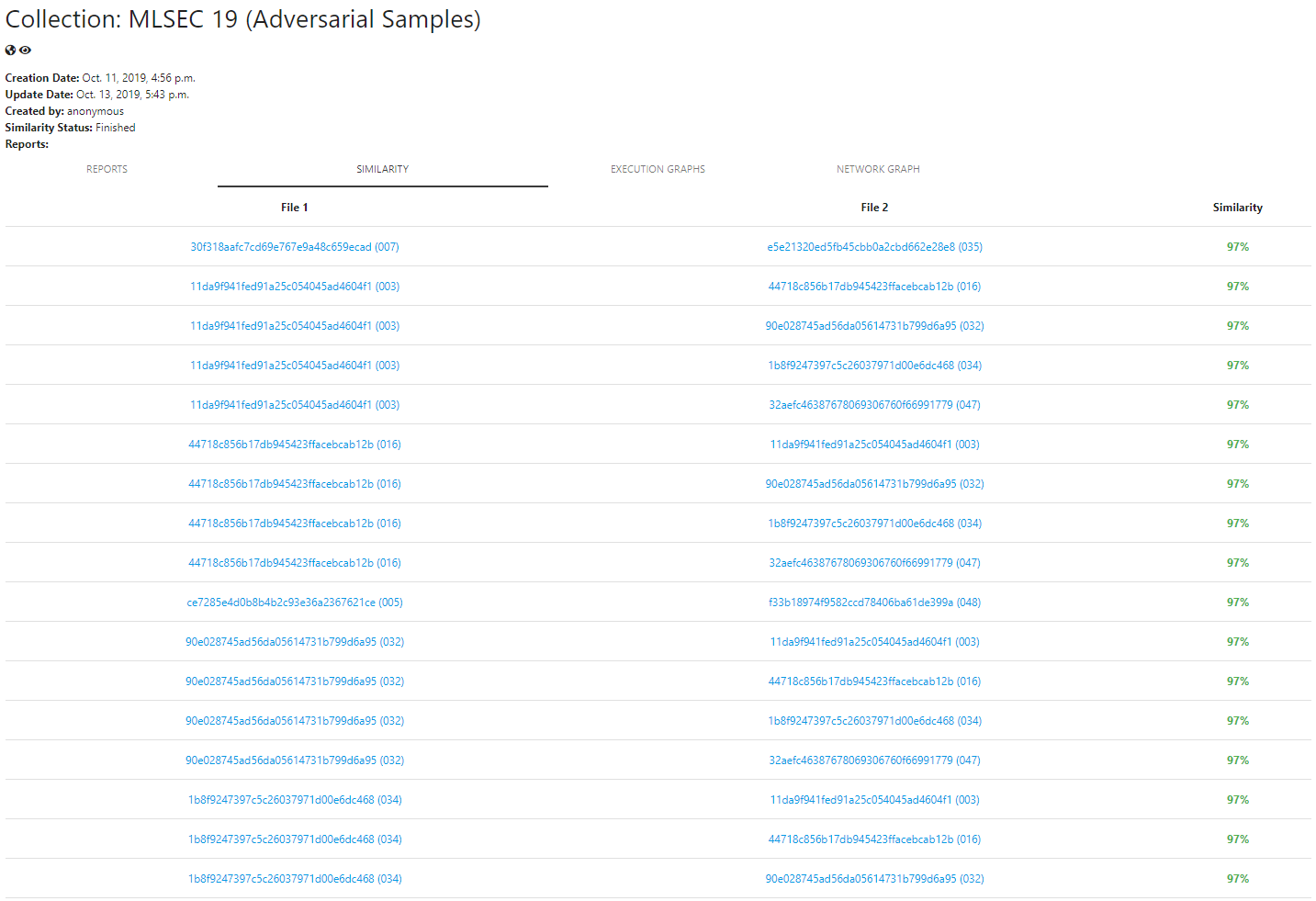
MLSEC 19 samples ssdeep similarity in our sandbox platform, Corvus.
The 2020 Challenge
This year, the MLSEC was sponsored by Microsoft and CUJO AI’s Vulnerability Research Lab and it was an incremental version of the 2019 edition, with one more additional step: generating ML malware detection models (Defender’s Challenge) to be further attacked by all the participants (Attacker’s Challenge).
In the Defender’s Challenge, the participants were free to develop their own ML defensive solutions, with models of their own choice and trained using any dataset and features. The defense solution should be saved in a docker image and need to meet three requirements: (i) it should accomplish less than 1% of False Positive Rate (FPR), (ii) less than 10% of False Negative Rate (FNR), and (iii) it must return a response within 5 seconds for any presented sample. Besides our model (needforspeed), another two met the proposed requirements: ember (provided by the organizers), and domumpqb (other participant). The results of this part of the challenge depend on how the attackers perform against each model, i.e., the one that performs better against adversarial attacks wins.
In the Attacker’s Challenge, all the three models that achieved the previous requirements were made available to be attacked by further black-box attacks, where the attackers have no knowledge about the detection models and have access only to the output produced by them. To do so, the organizers provided 50 unique Windows malware samples, which should be modified in order to bypass their detection in the defense solutions. Similar to last year’s challenge, the behavioral validation is accomplished by running the modified sample in a sandbox made available in the web site of the contest, which should result in the same IoCs of the original ones. Thus, each bypassed classifier for each binary accounts for 1 point, summing up to 150 points. Moreover, as a tiebreaker rule in case of similar bypass scores, the competition also considered the number of ML queries (number of times that samples are tested) used by each participant, which determines that the team that achieves the lowest number of queries wins.
The 50 samples provided by the organizers were submitted to VirusTotal API to check their family labels, which were normalized using AVClass. In the Figure below, we show the number of samples by malware families, with two families of them with higher prevalence (gamarue and remcos) and 30 families in total. We highlight here that all these malware were seen in the wild and may present real risks.
In order to better present our experience in both Defenders and Attacker’s challenges, in this blog post we highlight technical stuff for each step we made to create a fully functional model and adversarial samples.
Defender’s Challenge
To develop our defense solution, we used our experience from our paper “The Need for Speed: An Analysis of Brazilian Malware Classifiers”, which we tested several different ML classifiers to detect Brazillian malware using textual features (TF-IDF) on top of static analysis attributes, such as the list of libraries and functions used by a program. Thus, our first tests relied on the very same model used in our paper, the one that achieved the best classification performance, a Random Forest classifier trained using a Brazillian malware dataset, which we consider as being our baseline model. We further discovered that the nature of Brazilian samples was very different than of the world’s samples, thus we were not reaching high scores in the first phase. Thus, we decided to retrain our model with the same EMBER samples used in the last year. If we want to beat those classifiers, let’s use the same weapons!
To create the definitive version of our model, we selected the attributes from EMBER datasets, both 2017 and 2018, we believed to be less prone to be affected by adversaries. We categorized them into three types: numerical, which are integer or float numbers; categorical, which represents categories; and textual, which are a set of strings. Below, we list the attributes we selected for our model. The detailed description of all of them is available in the EMBER’s dataset paper and source code.
| TYPE | ATTRIBUTES |
| Numerical | string_paths, string_urls, string_registry, string_MZ, virtual_size, has_debug, imports, exports, has_relocations, has_resources, has_signature, has_tls, symbols, timestamp, numberof_sections, major_image_version, minor_image_version, major_linker_version, minor_linker_version, major_operating_system_version, minor_operating_system_version, major_subsystem_version, minor_subsystem_version, sizeof_code, sizeof_headers, sizeof_heap_commit |
| Categorical | machine, magic |
| Textual | libraries, functions, exports_list, dll_characteristics_list, characteristics_list |
To get these attributes from the EMBER dataset, we created the JSONAttributeExtractor class, which saves all of them into a dictionary, as shown in the Code below. The object is initialized with a single JSON file, i.e., a single line of any of EMBER’s .jsonl file. The method extract is then responsible for returning the dictionary containing only the attributes used by our model.
import json
class JSONAttributeExtractor():
# initialize extractor
def __init__(self, file):
# save data
self.data = json.loads(file)
# attributes
self.attributes = {}
# extract string metadata
def extract_string_metadata(self):
return {
'string_paths': self.data["strings"]["paths"],
'string_urls': self.data["strings"]["urls"],
'string_registry': self.data["strings"]["registry"],
'string_MZ': self.data["strings"]["MZ"]
}
# extract attributes
def extract(self):
# get general info
self.attributes.update({
"size": self.data["general"]["size"],
"virtual_size": self.data["general"]["vsize"],
"has_debug": self.data["general"]["has_debug"],
"imports": self.data["general"]["imports"],
"exports": self.data["general"]["exports"],
"has_relocations": self.data["general"]["has_relocations"],
"has_resources": self.data["general"]["has_resources"],
"has_signature": self.data["general"]["has_signature"],
"has_tls": self.data["general"]["has_tls"],
"symbols": self.data["general"]["symbols"],
})
# get header info
self.attributes.update({
"timestamp": self.data["header"]["coff"]["timestamp"],
"machine": self.data["header"]["coff"]["machine"],
"numberof_sections": len(self.data["section"]["sections"]),
"characteristics_list": " ".join(self.data["header"]["coff"]["characteristics"])
})
# get optional header
self.attributes.update({
"dll_characteristics_list": " ".join(self.data["header"]["optional"]["dll_characteristics"]),
"magic": self.data["header"]["optional"]["magic"],
"major_image_version": self.data["header"]["optional"]["major_image_version"],
"minor_image_version": self.data["header"]["optional"]["minor_image_version"],
"major_linker_version": self.data["header"]["optional"]["major_linker_version"],
"minor_linker_version": self.data["header"]["optional"]["minor_linker_version"],
"major_operating_system_version": self.data["header"]["optional"]["major_operating_system_version"],
"minor_operating_system_version": self.data["header"]["optional"]["minor_operating_system_version"],
"major_subsystem_version": self.data["header"]["optional"]["major_subsystem_version"],
"minor_subsystem_version": self.data["header"]["optional"]["minor_subsystem_version"],
"sizeof_code": self.data["header"]["optional"]["sizeof_code"],
"sizeof_headers": self.data["header"]["optional"]["sizeof_headers"],
"sizeof_heap_commit": self.data["header"]["optional"]["sizeof_heap_commit"]
})
# get string metadata
self.attributes.update(self.extract_string_metadata())
# get imported libraries and functions
self.libraries = " ".join([item for sublist in self.data["imports"].values() for item in sublist])
self.functions = " ".join(self.data["imports"].keys())
self.attributes.update({"functions": self.functions, "libraries": self.libraries})
# get exports
self.exports = " ".join(self.data["exports"])
self.attributes.update({"exports_list": self.exports})
# get label
self.label = self.data["label"]
self.attributes.update({"label": self.label})
return(self.attributes)
To train our model, we used 1.6 million labeled samples from EMBER datasets as input to the scikit-learn Random Forest with 100 estimators. To extract features from categorical attributes, we used scikit-learn OneHotEncoder, which transforms them into one-hot encoding arrays where each binary column represents a value (1 for present, 0 otherwise). The textual attributes are transformed into texts, separated by spaces. These texts were used as input to scikit-learn TfidfVectorizer, which transforms every text into a sparse array containing the TF-IDF values for the 300 top words in all the texts created (the ones with most frequency). Both categorical and textual features are then combined with the numerical attributes and normalized using scikit-learn MinMaxScaler to be used as input to train our model. This process is shown in the fit method of the NeedForSpeedModel class in the code below. This very same class is also used to predict the label and class probabilities of any new sample (represented as a pandas data frame built from a set of dictionaries extracted using our attribute extractor) after the training process is done, like any other scikit-learn classifier.
from copy import deepcopy
from sklearn.preprocessing import OneHotEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import RandomForestClassifier
# need for speed class
class NeedForSpeedModel():
# numerical attributes
NUMERICAL_ATTRIBUTES = [
'string_paths', 'string_urls', 'string_registry', 'string_MZ', 'size',
'virtual_size', 'has_debug', 'imports', 'exports', 'has_relocations',
'has_resources', 'has_signature', 'has_tls', 'symbols', 'timestamp',
'numberof_sections', 'major_image_version', 'minor_image_version',
'major_linker_version', 'minor_linker_version', 'major_operating_system_version',
'minor_operating_system_version', 'major_subsystem_version',
'minor_subsystem_version', 'sizeof_code', 'sizeof_headers', 'sizeof_heap_commit'
]
# categorical attributes
CATEGORICAL_ATTRIBUTES = [
'machine', 'magic'
]
# textual attributes
TEXTUAL_ATTRIBUTES = ['libraries', 'functions', 'exports_list',
'dll_characteristics_list', 'characteristics_list']
# label
LABEL = "label"
# initialize NFS classifier
def __init__(self,
categorical_extractor = OneHotEncoder(handle_unknown="ignore"),
textual_extractor = TfidfVectorizer(max_features=300),
feature_scaler = MinMaxScaler(),
classifier = RandomForestClassifier(n_estimators=100)):
self.base_categorical_extractor = categorical_extractor
self.base_textual_extractor = textual_extractor
self.base_feature_scaler = feature_scaler
self.base_classifier = classifier
# append features to original features list
def _append_features(self, original_features, appended):
if original_features:
for l1, l2 in zip(original_features, appended):
for i in l2:
l1.append(i)
return(original_features)
else:
return appended.tolist()
# train a categorical extractor
def _train_categorical_extractor(self, categorical_attributes):
# initialize categorical extractor
self.categorical_extractor = deepcopy(self.base_categorical_extractor)
# train categorical extractor
self.categorical_extractor.fit(categorical_attributes.values)
# transform categorical attributes into features
def _transform_categorical_attributes(self, categorical_attributes):
# transform categorical attributes using categorical extractor
cat_features = self.categorical_extractor.transform(categorical_attributes.values.tolist()).toarray()
# return categorical features
return cat_features.tolist()
# train a textual extractor
def _train_textual_extractor(self, textual_attributes):
# initialize textual extractors
self.textual_extractors = {}
# train feature extractor for each textual attribute
for att in self.TEXTUAL_ATTRIBUTES:
# initialize textual extractors
self.textual_extractors[att] = deepcopy(self.base_textual_extractor)
# train textual extractor
self.textual_extractors[att].fit(textual_attributes[att].values)
# transform textual extractor
def _transform_textual_attributes(self, textual_attributes):
# initialize features
textual_features = None
# extract features from each textual attribute
for att in self.TEXTUAL_ATTRIBUTES:
# train textual extractor
att_features = self.textual_extractors[att].transform(textual_attributes[att].values)
# transform into array (when it is an sparse matrix)
att_features = att_features.toarray()
# append textual features
textual_features = self._append_features(textual_features, att_features)
return textual_features
# train feature scaler
def _train_feature_scaler(self, features):
# initialize feature scaler
self.feature_scaler = deepcopy(self.base_feature_scaler)
# train feature scaler
self.feature_scaler.fit(features)
# transform features using feature scaler
def _transform_feature_scaler(self, features):
return self.feature_scaler.transform(features)
# train classifier
def _train_classifier(self,features,labels):
# initialize classifier
self.classifier = deepcopy(self.base_classifier)
# train feature scaler
self.classifier.fit(features, labels)
# fit classifier using raw input
def fit(self, train_data):
# get labels
train_labels = train_data[self.LABEL]
# delete label column
del train_data[self.LABEL]
# initialize train_features with numerical ones
train_features = train_data[self.NUMERICAL_ATTRIBUTES].values.tolist()
print("Training categorical features...")
# train categorical extractor
self._train_categorical_extractor(train_data[self.CATEGORICAL_ATTRIBUTES])
# transform categorical data
cat_train_features = self._transform_categorical_attributes(train_data[self.CATEGORICAL_ATTRIBUTES])
# append categorical_features to train_features
train_features = self._append_features(train_features, cat_train_features)
print("Training textual features...")
# train textual extractor
self._train_textual_extractor(train_data[self.TEXTUAL_ATTRIBUTES])
# transform textual data
tex_train_features = self._transform_textual_attributes(train_data[self.TEXTUAL_ATTRIBUTES])
# append textual_features to train_features
train_features = self._append_features(train_features, tex_train_features)
print("Normalizing features...")
# train feature normalizer
self._train_feature_scaler(train_features)
# transform features
train_features = self._transform_feature_scaler(train_features)
print("Training classifier...")
# train classifier
return self._train_classifier(train_features, train_labels)
def _extract_features(self,data):
# initialize features with numerical ones
features = data[self.NUMERICAL_ATTRIBUTES].values.tolist()
print("Getting categorical features...")
# transform categorical data
cat_features = self._transform_categorical_attributes(data[self.CATEGORICAL_ATTRIBUTES])
# append categorical_features to features
features = self._append_features(features, cat_features)
print("Getting textual features...")
# transform textual data
tex_features = self._transform_textual_attributes(data[self.TEXTUAL_ATTRIBUTES])
# append textual_features to features
features = self._append_features(features, tex_features)
print("Normalizing features...")
# transform features
features = self._transform_feature_scaler(features)
# return features
return(features)
def predict(self,test_data):
# extract features
test_features = self._extract_features(test_data)
print("Predicting classes...")
# predict features
return self.classifier.predict(test_features)
def predict_proba(self,test_data):
# extract features
test_features = self._extract_features(test_data)
print("Predicting classes...")
# predict features
return self.classifier.predict_proba(test_features)
Using both modules presented so far, it is possible to train our model and save it using pickle. This way it can be further used to check the prediction of a single Portable Executable file, as any real Anti Virus would do. The code below presents the training process of our model, considering that the jsonl files containing the attributes used to train it are present in the “files” list, in our case EMBER 2017 and 2018 datasets’ files.
import json
import pickle
import pandas as pd
from json_attribute_extractor import JSONAttributeExtractor
from need_for_speed_model import NeedForSpeedModel
# list of files used to train the model in
# the same format as ember 17' and 18'
# datasets
files = [
"ember_2017_2/train_features_0.jsonl",
"ember_2017_2/train_features_1.jsonl",
"ember_2017_2/train_features_2.jsonl",
"ember_2017_2/train_features_3.jsonl",
"ember_2017_2/train_features_4.jsonl",
"ember_2017_2/train_features_5.jsonl",
"ember_2017_2/test_features.jsonl",
"ember2018/train_features_0.jsonl",
"ember2018/train_features_1.jsonl",
"ember2018/train_features_2.jsonl",
"ember2018/train_features_3.jsonl",
"ember2018/train_features_4.jsonl",
"ember2018/train_features_5.jsonl",
"ember2018/test_features.jsonl"
]
if __name__=='__main__':
train_attributes = []
# walk in files
for input in files:
# read input file
file = open(input, 'r')
# read its lines
sws = file.readlines()
# walk in each sw
for sw in sws:
# initialize extractor
at_extractor = JSONAttributeExtractor(sw)
# get train_attributes
atts = at_extractor.extract()
# save attribute
train_attributes.append(atts)
# close file
file.close()
# create pandas dataframe with train attributes
train_data = pd.DataFrame(train_attributes)
# get train data that have label
train_data = train_data[(train_data["label"]==1) | (train_data["label"]==0)]
# initialize nfs model
clf = NeedForSpeedModel()
# train model
clf.fit(train_data)
# save model
with open('nfs.pickle', 'wb') as f:
pickle.dump(clf, f)
Given that EMBER dataset is available only in JSON format (with all the attributes already extracted), we also created a module that extracts the very same attributes from raw PE binaries, as an alternative to JSONAttributeExtractor. This module, called PEAttributeExtractor, as shown in the code below, is used to test attackers’ samples, and it also could be used by any real-world testing solution. The original solution of our baseline model was deployed on top of pefile module, but it did not achieve the required performance by the challenge, resulting in classification timeout, i.e., some samples were taking more than 5 seconds to be parsed, which made necessary to port our solution to life, the same module used by ember model. As a consequence, the same aforementioned samples were taking about 2 seconds when using lief as the parser, but its parsing results are a bit different than pefile, which required to slightly change our model to consider some attributes (machine and magic) as categorical instead of numerical.
import re
import math
import lief
class PEAttributeExtractor():
libraries = ""
functions = ""
exports = ""
# initialize extractor
def __init__(self, bytez):
# save bytes
self.bytez = bytez
# parse using lief
self.lief_binary = lief.PE.parse(list(bytez))
# attributes
self.attributes = {}
# extract string metadata
def extract_string_metadata(self):
# occurances of string 'C:\'
paths = re.compile(b'c:\\\\', re.IGNORECASE)
# occurances of http:// or https://
urls = re.compile(b'https?://', re.IGNORECASE)
# occurances of string prefix HKEY_
registry = re.compile(b'HKEY_')
# evidences of MZ header
mz = re.compile(b'MZ')
return {
'string_paths': len(paths.findall(self.bytez)),
'string_urls': len(urls.findall(self.bytez)),
'string_registry': len(registry.findall(self.bytez)),
'string_MZ': len(mz.findall(self.bytez))
}
# extract entropy
def extract_entropy(self):
if not self.bytez:
return 0
entropy=0
for x in range(256):
p_x = float(self.bytez.count(bytes(x)))/len(self.bytez)
if p_x>0:
entropy += - p_x*math.log(p_x, 2)
return entropy
# extract attributes
def extract(self):
# get general info
self.attributes.update({
"size": len(self.bytez),
"virtual_size": self.lief_binary.virtual_size,
"has_debug": int(self.lief_binary.has_debug),
"imports": len(self.lief_binary.imports),
"exports": len(self.lief_binary.exported_functions),
"has_relocations": int(self.lief_binary.has_relocations),
"has_resources": int(self.lief_binary.has_resources),
"has_signature": int(self.lief_binary.has_signature),
"has_tls": int(self.lief_binary.has_tls),
"symbols": len(self.lief_binary.symbols),
})
# get header info
self.attributes.update({
"timestamp": self.lief_binary.header.time_date_stamps,
"machine": str(self.lief_binary.header.machine),
"numberof_sections": self.lief_binary.header.numberof_sections,
"numberof_symbols": self.lief_binary.header.numberof_symbols,
"pointerto_symbol_table": self.lief_binary.header.pointerto_symbol_table,
"sizeof_optional_header": self.lief_binary.header.sizeof_optional_header,
"characteristics": int(self.lief_binary.header.characteristics),
"characteristics_list": " ".join([str(c).replace("HEADER_CHARACTERISTICS.","") for c in self.lief_binary.header.characteristics_list])
})
try:
baseof_data = self.lief_binary.optional_header.baseof_data
except:
baseof_data = 0
# get optional header
self.attributes.update({
"baseof_code": self.lief_binary.optional_header.baseof_code,
"baseof_data": baseof_data,
"dll_characteristics": self.lief_binary.optional_header.dll_characteristics,
"dll_characteristics_list": " ".join([str(d).replace("DLL_CHARACTERISTICS.", "") for d in self.lief_binary.optional_header.dll_characteristics_lists]),
"file_alignment": self.lief_binary.optional_header.file_alignment,
"imagebase": self.lief_binary.optional_header.imagebase,
"magic": str(self.lief_binary.optional_header.magic).replace("PE_TYPE.",""),
"PE_TYPE": int(self.lief_binary.optional_header.magic),
"major_image_version": self.lief_binary.optional_header.major_image_version,
"minor_image_version": self.lief_binary.optional_header.minor_image_version,
"major_linker_version": self.lief_binary.optional_header.major_linker_version,
"minor_linker_version": self.lief_binary.optional_header.minor_linker_version,
"major_operating_system_version": self.lief_binary.optional_header.major_operating_system_version,
"minor_operating_system_version": self.lief_binary.optional_header.minor_operating_system_version,
"major_subsystem_version": self.lief_binary.optional_header.major_subsystem_version,
"minor_subsystem_version": self.lief_binary.optional_header.minor_subsystem_version,
"numberof_rva_and_size": self.lief_binary.optional_header.numberof_rva_and_size,
"sizeof_code": self.lief_binary.optional_header.sizeof_code,
"sizeof_headers": self.lief_binary.optional_header.sizeof_headers,
"sizeof_heap_commit": self.lief_binary.optional_header.sizeof_heap_commit,
"sizeof_image": self.lief_binary.optional_header.sizeof_image,
"sizeof_initialized_data": self.lief_binary.optional_header.sizeof_initialized_data,
"sizeof_uninitialized_data": self.lief_binary.optional_header.sizeof_uninitialized_data,
"subsystem": str(self.lief_binary.optional_header.subsystem).replace("SUBSYSTEM.","")
})
# get entropy
self.attributes.update({
"entropy": self.extract_entropy()
})
# get string metadata
self.attributes.update(self.extract_string_metadata())
# get imported libraries and functions
if self.lief_binary.has_imports:
self.libraries = " ".join([l for l in self.lief_binary.libraries])
self.functions = " ".join([f.name for f in self.lief_binary.imported_functions])
self.attributes.update({"functions": self.functions, "libraries": self.libraries})
# get exports
if self.lief_binary.has_exports:
self.exports = " ".join([f.name for f in self.lief_binary.exported_functions])
self.attributes.update({"exports_list": self.exports})
return(self.attributes)
When testing our model with last year’s samples we reported that it achieved a
False Positive Rate (FPR) of 8.5%, which did not meet the competition requirements of 1%. Thus, to fine-tune our model and improve the FPR, we created a new prediction function that uses the model class probabilities as input. To do so, we defined a threshold 𝑇 and used it to define the output class: if the probability of being goodware is greater than 𝑇, the current sample will be classified as goodware. Otherwise, it will be classified as malware. With a threshold 𝑇 = 80%, our model managed to perform as required by the competition, achieving less than 0.1% of FPR. In order to implement this threshold, we implemented a wrapper class called NFSWrapper, as shown in the code below, which takes as initialization parameter the opened pickle file and the threshold (0.8 by default). The predict function takes the file bytes as input, extracts its attributes using PEAttributeExtractor, and gets its prediction probabilities from the classifier to create a new prediction and normalized class probability based on the threshold value.
import pickle
import lief
import pandas as pd
from pe_attribute_extractor import PEAttributeExtractor
class NFSWrapper():
def __init__(self, model, threshold = 0.8):
# load model
self.clf = pickle.load(model)
# set threshold
self.threshold = threshold
def predict(self, bytez: bytes) -> int:
try:
# initialize attribute extractor
pe_att_ext = PEAttributeExtractor(bytez)
# extract attributes
atts = pe_att_ext.extract()
# create dataframe
atts = pd.DataFrame([atts])
# predict sample probability
prob = self.clf.predict_proba(atts)[0]
# get prediction according to gw probability
pred = int(prob[0] < self.threshold)
# calc probability
if pred:
# calc normalized mw probality
prob[pred] = 0.5 + ((self.threshold-prob[0])/self.threshold)*0.5
else:
# calc normalized gw probality
prob[pred] = 0.5 + ((prob[0]-self.threshold)/(1-self.threshold))*0.5
except (lief.bad_format, lief.read_out_of_bound) as e:
# error parsing PE file, we considere
# it's a malware
print("Error: ", e)
pred = 1
prob = [0, 1]
# return prediction and probability
return(int(pred), prob[pred])
To test our model in a real PE file, as required in the attacker’s challenge, we just need to initialize the NFSWrapper class with a valid pickle file (containing the trained model) and then use it to predict the class and probabilities of the input file from sys.argv[1], as shown in the code below.
import sys
from nfs_wrapper import NFSWrapper
# initialize classifier with
# pre-trained model
clf = NFSWrapper(open("nfs.pickle", "rb"))
# open test file
test_file = open(sys.argv[1],'rb')
# get its bytes
bytez = test_file.read()
# predict pe file
pred, prob = clf.predict(bytez)
# print probabilities
print("Prediction: ", pred)
print("Probability: ", prob)
After fully implementing our model, as an initial test, we submitted the adversarial samples provided by the organizers (594 samples, all variations from the original 50 samples from the 2019 challenge) from last year’s challenge to it and analyzed their detection rate. Our model was able to detect 88.91% of these samples. Considering that all the 2019’s models were bypassed by those samples, we agreed that it was a significant-good result. It is important to note that we confirmed our findings from last year that models based on parsing PE files are better than the ones that make use of raw data. Finally, our model is open-source and available in this repository.
Attacker’s Challenge
Based on our previous knowledge gathered in the last year’s competition and on our existing infrastructure, the attacker’s challenge becomes basically a straightforward application of them. We had already knowledge on how to bypass previous models, we had an implemented dropper to embed files, and we had a local infrastructure to test samples without making queries to the challenge one.
As soon as the attacker challenge opened, we started submitting the files appended with strings to bypass the model that we knew from last year. Of course, we didn’t have the same model implemented in this year, but we guessed that bypassing the last year’s model locally would suffice to also bypass the remote GDM model trained with new samples. We achieved a reasonable number of bypasses in the first attempts. Then, we took a break to solve other academic issues. A nice thing about this year’s challenge is that it remained open for a while (6 weeks), which allowed us to make things without hurrying up too much.
Back to the competition, we were not leading the scoreboard, but we knew how to do, then we focused our attention on bypassing our own model. We knew a lot about our model, so it was easy. Since it was based on textual features, we added a lot of goodware ones to the binaries until the classifier was convinced it was a goodware. More technically, since our model looks for the imported functions and libraries, we added a bunch of dead imports in our dropper, as you can see. At this time, 2 out of 3 models have gone.
| void dead() | |
| { | |
| return; | |
| memcpy(NULL,NULL,NULL); | |
| memset(NULL,NULL,NULL); | |
| strcpy(NULL,NULL); | |
| ShellAboutW(NULL,NULL,NULL,NULL); | |
| SHGetSpecialFolderPathW(NULL,NULL,NULL,NULL); | |
| ShellMessageBox(NULL,NULL,NULL,NULL,NULL); | |
| RegEnumKeyExW(NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL); | |
| RegOpenKeyExW(NULL,NULL,NULL,NULL,NULL); | |
| RegEnumValueW(NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL); | |
| RegGetValueW(NULL,NULL,NULL,NULL,NULL,NULL,NULL); |
So far, we had bypassed 2/3 models and we still need to bypass the third one, a completely unknown model. When looking at our scores, we noticed that our dropper+dead code approach had succeeded in bypassing the third models for some samples, but not for others. Since the same droppers were used and importing the same libraries, only one thing could be happening: the classifier was detecting the embedded payload (or parts of it, such as strings). The solution? Hide the payload!
We first armored our dropper with a single-byte XOR “encryption”. It was easy since it was prepared for it. This bypassed the third model in most cases. A few samples were missing, then we tried a distinct encoding: base64. It succeeded! Later, we also tried distinct XOR keys, which also succeeded! We were the first to bypass all models and the challenge had still 3 weeks until its end…
The dropper operation has some drawbacks, one of them was stressed in this year’s challenge, so it is worth a mention. When you embed a file into a dropper, you have to launch the malware process by yourself. In the original malware, this task was a sandbox due. In most cases, nothing special is required, just run the binary as usual, with no arguments, and things go well. However, one of the provided samples was a DLL… As you know, DLLs cannot be executed with a double click but should be injected in some process. We did not realize that in the first submissions, so we got some extra failures. We then modified our dropper to inject it in a host process, as below.
| #ifdef INJECT | |
| char cmd[10*NAME_SIZE] = "C:\\Windows\\system32\\rundll32.exe"; | |
| sprintf(args,"%s %s,#1",cmd,name); | |
| CreateProcessA(cmd,args,NULL,NULL,FALSE,0,NULL,NULL,&si,&pi ); |
The Final Results
In the defender’s challenge, our model finished in the second position, with 165 evasions, behind domumpbq model, with a good advantage over ember, as shown in the Table below. We are not sure about how representative this result is since it depends on the attacker’s abilities to bypass the models. Anyway, we consider this result positive, given that we did not focus on any specific strategy to deal with adversarial samples rather than establishing a threshold, as we already presented. Also, considering that ember was the best defense solution in last year’s challenge, we consider this as an evolution. As future work, we plan to use all the data created in this competition to improve our research model.
| DEFENDER NAME | NUMBER OF EVASIONS |
| domumpbq | 65 |
| needforspeed | 165 |
| ember (sample solution) | 270 |
For the attacker challenge, we ended up being the only team to bypass all models: 1st place this time!
|
ATTACKER NAME |
EVASION SCORE | API QUERIES |
|
needforspeed |
150 |
741 |
| wunderwuzzi23 | 48 |
378 |
|
alala |
44 |
150 |
|
matrix |
15 | 3636 |
|
reevesrs24 |
10 |
723 |
At the moment we are writing, two competitors presented their write-up (this post will be updated in case new blog posts are published).
The first position in the defender’s challenge presented their experience, presenting their solution that combines multiple defenses by addressing the semantic gap, using various classification models, and applying a stateful defense.
The second position in the attacker’s challenge presented an interesting signature-based approach that succeeded in bypassing the models for some binaries. We are not sure what happened, but we believe that is due to the strings generated due to the signature process since our model does not use signature data but was bypassed for a few cases.
Future Plans
We believe that this challenge is very important for the community, so we have some suggestions for future years: (i) include the evaluation of False Positives (FPs) in all steps. We noticed that the models were so biased towards detection malware and variants that most goodware (files from the Windows system folder) were mislabelled as malware. This would make these classifiers impractical for a real-world operation; (ii) create distinct competition classes. The detection of droppers is only possible if these are first extracted from the main binary and classified. Unfortunately, with the existing timing constraints, a feature extractor would timeout before extracting the embedded payload. We know that distinct operational scenarios require distinct approaches, therefore, we suggest creating distinct categories of timeouts. Some categories/classifiers aiming to be fast, some aiming to detect everything…
Giving Back to the Community
We are grateful for the opportunity to participate in this challenge and to learn a lot. We would like that anyone has the opportunity to learn as well. Therefore, as in previous years, we are making available a set of resources to anyone interested.
First, our defender solution is totally open-source and can be used to develop new defense solutions in the future. You can check all the codes provided by this post in this repository.
Also, we are opening the source-code of our Dropper, with all the improvements, as you can check here.
If you prefer to try the dropper online, you can do that in our sandbox solution. Just click in “Generate Adversarial” and you will trigger an automatic procedure to embed whatever PE file you upload in a dropper. You can then go to the ML tab on the results page to check if the classifiers were evaded.
Generate adversarial is Corvus’ totally new feature.
Finally, we enhanced our sandbox with multiple visualization tools to help you understand how the dropper work. In the figure below, you can compare the interactions performed by the Original vs Adversarial samples. Notice that they are very similar and only differ due to the dropper process itself.


Acks
We really thanks the competition organizers for this amazing opportunity. Hope to see you all again next year!
About the Authors

Fabrício Ceschin
B.Sc., CS @UFPR, 2016
MSc, CS @UFPR, 2018
PhD, CS @UFPR, 2023




Marcus Botacin
Computer Eng. @UNICAMP, 2015
MSc, CS @UNICAMP, 2017