Another year, another edition of the Machine Learning Security Evasion Competition (MLSEC) took place! If you don’t know what we are talking about, it is a competition promoted by some well-known Internet companies (CUJO AI, Microsoft, MRG Effitas, VMRay, and Nvidia) in which one has (i) to develop machine learning-based malware detectors (Defender Challenge); and (ii) attack other competitor’s models with evasive malware (Attacker Challenge). The challenge is currently in its 3rd edition and, almost as a tradition, SECRET participated this year again. Below we describe our experiences this year.
The Previous Challenges
The challenge has been evolving with years and SECRET has been evolving as well. In the first year, the challenge encompassed only the attack phase, in which we had to modify 50 so-far detected malware samples to evade some organization-provided classifiers. SECRET was able to bypass all classifiers, which gave us the 2nd position (in a tie with the 1st place). By that time, our strategy consisted mostly of adding junk data to files to bypass models looking at raw bytes, as we published in an academic article.
Last year’s challenge evolved to a defense-attack model, in which we also had to develop a malware detector. We explained the overall rules in a blog post. We finished last year’s challenge in 2nd place in the defender challenge and 1st place in the attacker challenge, being able to bypass all models for all samples. Our defense solution was a Random Forest classifier trained with features extracted from the EMBER dataset by using TF-IDF. Our attack strategy shifted from appending data to embedding samples in a dropper file that prevented inspection by encoding payloads in base64 and/or using XOR keys. Both of our defensive and offensive solutions are also detailed in an academic paper.
What We Asked For
Our attacker strategy for last year’s competition could be automated by embedding any payload into our dropper and launching a new process with it (in fact, we implemented this feature in Corvus, our threat analysis platform). It was possible because most samples were very similar (typical PE files), with almost no diversity in their generation. The only exception was a single DLL file that required us to modify our dropper to inject the payload rather than directly execute it. Therefore, our suggestion for the next edition (current year) was to diversify file formats.
The 2021’s Challenge

New modalities: In this year’s competition, In addition to the malware binary attacker and defense, the challenge proposed a phishing evasion competition. Unfortunately, we didn’t have time to participate in this new category. Instead, we focused on the binary competition, our specialty, and a SECRET tradition.
A new rule: In this year’s competition, droppers were not allowed, according to rule 3c: “Solutions that include self-extracting archives or droppers, wherein the original malware sample is a payload, will be rejected after the contest concludes. (Please note, that this is a new rule from previous years.)“. This means that our dropper would have to be modified to operate in a distinct way. We initially didn’t like this new rule because we think that artificial constraints do not reflect reality, where attackers will do whatever is easier for them. However, we accepted the organization’s argument that if we dropped the original payload to the disk, it would be detected by a real-time AV anyway. This is true, but it will have implications as we will further discuss in the attacker’s step description.
More diverse samples: Following our suggestions (or not, who knows?), this year’s challenge is much more varied in file types, as shown in Figure below, including not only typical EXEs, but also 64 bits EXEs, DLLs, .Net binaries, and NSIS installers. This certainly made the challenge more interesting and solutions harder to automate.
The Defender Challenge
Our Model: Our model for this year’s competition was very similar to the last one, which includes using the same classifier (Random Forest), and almost the same attributes with a new feature extractor (instead of using TF-IDF). First of all, we removed all the features related to strings (number of paths, URLs, registry keys, and MZ headers), which we believed was one of the failures of our last year’s model given that strings may be easily modified, removed, and/or added to the binaries. Also, we included more textual features that were available in EMBER dataset, such as exports_list, dll_characteristics_list e characteristics_list. Finally, we changed our feature extraction method to HashingVectorizer, which produces features that are most resistant to attacks, as we can see in the table below, where all models were trained using EMBER dataset and tested with all the previous MLSEC adversarial samples provided by the organization. According to this experiment, HashingVectorizer drastically reduces the number of false negatives (almost 16 percentage points of difference in recall) in comparison to TF-IDF, even when using the very same features. Note that we tested several different classifiers and strategies, such as SGDClassifier and CountVectorizer, but Random Forest and HashingVectorizer still outperformed them. In addition, HashingVectorizer makes a lot of sense when it comes to online learning procedures (real-world solutions), given that it does not require to be updated with a new vocabulary as time goes by.
| Model | F-Score | Recall | Precision |
| Last Year’s Challenge (TF-IDF, 2020 Model) |
0.62% | 0.31% | 100% |
| TF-IDF without String Features and with more Textual Features |
20.86% | 11.65% | 100% |
| HashingVectorizer without String Features and with more Textual Features (2021 Model) |
43.12% | 27.48% | 100% |
Tuning the Model: Our strategy for the competition was to tune our model in a very aggressive way so as to detect the most samples possible, without increasing the false positive rate significantly. We performed some experiments considering two factors: (i) training dataset, i.e., the dataset used to train the model, and (ii) model threshold, i.e., the probability considered by the classifier to consider a given binary a goodware. According to our last year’s experience, training the very same model using the adversarial samples provided by the organizers did not help to improve classification performance. Nevertheless, we still tested this hypothesis considering our new model and a test dataset containing all the adversarial samples provided by the organizers this year (samples from the 2019 and 2020 editions) and goodware collected from a pristine Windows installation. To do so, we created three training sets: (i) EMBER labeled samples (~1mi samples), (ii) EMBER labeled samples (~1mi samples) and MLSEC 2019 adversarial samples (594 samples), and (iii) EMBER labeled samples and MLSEC 2020 adversarial samples (50 samples). As shown in the Figure below, the model trained with dataset (i) presents a very high False Negative Rate (FNR), as expected, given that it does not know any adversarial sample.
In contrast, as we can see in the Figure below, the model trained with dataset (ii) presents a very high False Positive Rate (FPR), which means that the bigger the threshold, the more it considers any file as being malware, something already expected considering the experiments we did last year where the classifier considered everything as malware after being trained with adversarial samples.
Finally, as seen in the Figure below, the model trained with dataset (iii) presented quite a good balance at some threshold values, with relatively low FNRs and FPRs, which means that the MLSEC 2020 adversarial samples produced help to detect 2019 ones. Thus, according to all the results presented, we selected the model trained with dataset (iii) with 75% of threshold, given that it presented a very low FNR (0.31%) and FPR (2.57%). Note that we tested several other training datasets we have in our private repositories, but none of them provided better results than the ones presented here.
Model’s Biases: Even after performing all the experiments we presented, we still wanted to understand how the model would perform against goodware from multiple different sources. To do so, we tested our model with some goodware datasets that we have in our research repository (such as the dataset used in our bundle paper) and compared its results with the EMBER model. As we can see in the Figures below, “there is no free lunch”. Despite presenting a very low FNR, our model only has a low FPR when detecting pristine Windows Apps. In all other scenarios, almost everything is considered malware. This also happens with our 2020 model (even though we haven’t been so aggressive that year) and EMBER (LightGBM model), but with much less frequency.
Thus, our final result was a very aggressive classification model that detects almost everything as malicious. The only constraint for the model’s aggressiveness was that our model should survive the goodware tests performed to validate the model at the submission time (according to the competition rules “the model must perform at a false negative rate not exceeding 10% – “Maximum FN rate” – and a false positive rate not exceeding 1% – “Maximum FP rate” -, when evaluated against samples curated by Microsoft and Contest Parties”). It happens that the samples used in this validation step are very limited and do not reflect the reality of a user machine. Once our model passed the validation, it revealed itself to be very aggressive in detecting malware, which shows that sometimes overfitting is rewarded!
Suggestions for the future: Considering the biases we found about detecting goodware, if the challenge aims to reflect real-world operation conditions, it should consider more varied and diverse goodware samples. To make the challenge more interesting, we suggest allowing the submissions of goodware samples in addition to malware samples so one could trick the classifier into classifying goodware as malware in addition to malware as goodware.
The Challenge Results: Considering our model, at the time we wrote this blog post (we will update it in the future with the final results), in practice it resulted in the most resistant model of the competition, with 162 samples bypassing it against 193 from the model in the second position (in this year competition, we had six models submitted). It is important to note that our model had issues with docker memory limitation during the attacker challenge, making it freeze its execution. As a consequence, we lost some points, given that any sample submitted (that performed the same Indicators of Compromise – IOCs – as the original files) during the time it was frozen was considered goodware. Such a problem happened because we did not set any parameters (such as max_depth, min_samples_leaf, etc) to reduce the size of the scikit-learn’s Random Forest trees. We just noticed this problem during the attacker challenge, even after performing a lot of tests in our local machines with docker memory limitation (1.5GB) and submitting it during the defender challenge (it ran successfully after uploaded, even with memory constraints). Finally, considering all the 3,874 bypasses, our model presented a bypass rate of 4.18% (extra official results). The results (so-far) are shown in the Table below.
| Model | # of Bypasses |
| secret (our model) | 162 |
| A1 | 193 |
| kipple | 231 |
| scanner_only_v1 | 714 |
| model2_thresh_90 | 734 |
| submission 3 | 1840 |
Reproducibility: All the codes used to train and use our defender is publicly available at our GitHub repository. The only changes from the previous model (named NeedForSpeed) are: (i) we are using HashingVectorizer with 50K features for each textual attribute (instead of using TFIDFVectorizer with 300 features), (ii) we are using new textual features (such as exports_list, dll_characteristics_list, and characteristics_list), and (iii) we removed all the features related to strings, as already mentioned. A code snippet containing the class declaration of our model can be seen below.
| # This is only a code snippet extracted from | |
| # https://github.com/fabriciojoc/2021-Machine-Learning-Security-Evasion-Competition/blob/master/defender/train_classifier.py | |
| class NeedForSpeedModel(): | |
| # numerical attributes | |
| NUMERICAL_ATTRIBUTES = [ | |
| 'virtual_size', 'has_debug', 'imports', 'exports', 'has_relocations', | |
| 'has_resources', 'has_signature', 'has_tls', 'symbols', 'timestamp', | |
| 'numberof_sections', 'major_image_version', 'minor_image_version', | |
| 'major_linker_version', 'minor_linker_version', 'major_operating_system_version', | |
| 'minor_operating_system_version', 'major_subsystem_version', | |
| 'minor_subsystem_version', 'sizeof_code', 'sizeof_headers', 'sizeof_heap_commit' | |
| ] | |
| # categorical attributes | |
| CATEGORICAL_ATTRIBUTES = [ | |
| 'machine', 'magic' | |
| ] | |
| # textual attributes | |
| TEXTUAL_ATTRIBUTES = ['libraries', 'functions', 'exports_list', | |
| 'dll_characteristics_list', 'characteristics_list'] | |
| # label | |
| LABEL = "label" | |
| # initialize NFS classifier | |
| def __init__(self, | |
| categorical_extractor = OneHotEncoder(handle_unknown="ignore"), | |
| textual_extractor = HashingVectorizer(n_features=50000, token_pattern=r"(?<=\s)(.*?)(?=\s)"), | |
| feature_scaler = MaxAbsScaler(), | |
| classifier = RandomForestClassifier()): | |
| self.base_categorical_extractor = categorical_extractor | |
| self.base_textual_extractor = textual_extractor | |
| self.base_feature_scaler = feature_scaler | |
| self.base_classifier = classifier | |
| ... |
The Attacker Challenge
Previous year strategy: We assumed in last year’s competition that bypassing our model would be enough to bypass any other model, which ended up being revealed true. Thus, our strategy in last year’s competition was to develop a dropper that mimics a goodware sample so as to trick the classifier into classifying the dropper as goodware. By that ocasion, we developed a dropper that mimics the native Windows calculator by adding dead function imports to it.
This year’s strategy: Our strategy for this year’s competition was very similar. We assumed that bypassing our model would be enough to also bypass other models in most cases, especially because our model was very aggressive towards the malware class. Due to this characteristic, we didn’t find any goodware samples with a significant number of imports classified as goodware to mimic, which impeded us from repeating our strategy. However, we discovered that the native Windows NTDLL was classified as goodware and had a significant number of exports, such that we could mimic it by adding lots of fake exports with the same name as the ones from NTDLL to our dropper and letting it to bias the classifier towards the goodware class.
No filesystem artifacts: We initially only converted our dropper from a typical EXE to DLL and started embedding payloads, which was enough to bypass all classifiers in the first attempt. However, we noticed the new rule that no filesystem dropping was allowed and we had to change our approach. We decided then to adopt a memory-based approach (RunPE or ProcessHollowing), in which we would still embed an encoded payload and extract it in memory, but instead of dropping it to the disk, we would patch an existing process memory with this content. Our first attempt was to do it using our own process, but it seems that the rundll32 process used to run our Dropper DLL doesn’t like too much being injected and patched, at least in the challenge’s sandbox (even though it worked in our local machine). We understood then that we needed to create a process that “likes” to be injected and patched. But, there was a restriction: it shouldn’t be detected by the classifiers when dropped the disk (that was the goal behind not allowing filesystem droppers, right?). We then discovered another bias in our model: .Net executables. It seems that our model does not detect .Net binaries very well due to the import of the mscoree library by all samples (goodware and malware). This was enough to allow us to create a Hello World in .Net and embed it in the dropper. Therefore, each time the dropper runs, it drops a Hello World file that is not malicious, but the process created from it is turned into malicious in run-time by injecting the original malware payload in it. In the end, the hello world application is the only forensic artifact remaining in the system.
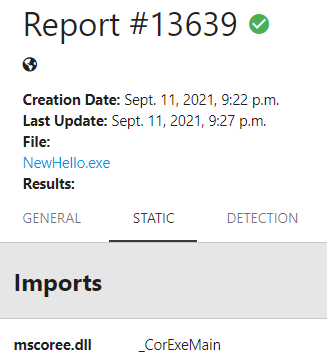
NewHello importing mscoree.dll, report available here.
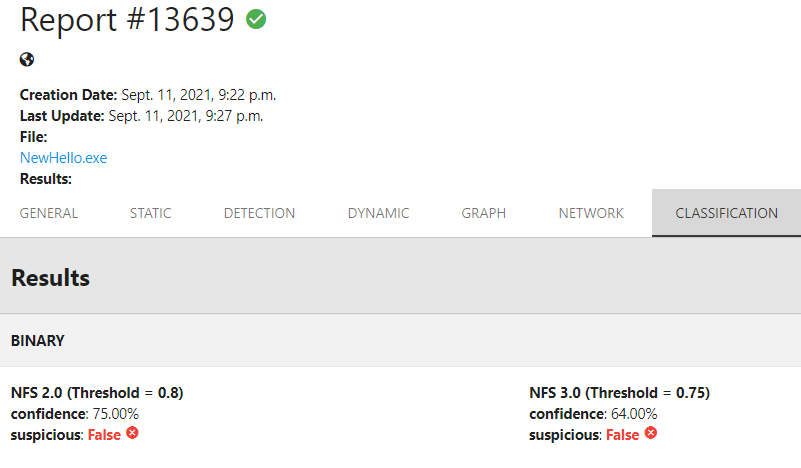
NewHello classification results, report available here.
Sandbox Problems: To score points in the challenge, the submitted samples must bypass the classifiers and still perform the same actions as the reference, original ones. During the challenge, we faced many problems with this IOC validation step in the challenge sandbox. We still don’t know what happened in most cases, but we thank the organization for their efforts in manually validating submissions and providing feedback whenever possible.
Suggestion for next edition: The more we modify the samples, like making them work from memory, the greater the chance of them performing differently than the reference IOCs. This might be even due to natural causes, like randomized execution, thus we suggested not only validating if the same IOCs were generated but the proportion of the IOCs generated. Maybe it might even be used to score fractionated points according to how much of a sample has run or not. We believe this still reflects the real world because modern malware is often multi-step and not performing one of them or performing them multiple times does not necessarily mean a failed infection.
Special Cases: The diverse samples provided this year definitely made the challenge more interesting, but it also implied some drawbacks. We following discuss two specific cases.
Samples calling themselves: In the previous year, by dropping the filesystem to the disk, we were able to bypass all classifiers for all samples. This year, with the memory injection strategy, this is not possible, since some samples were not designed to be injected this way. Some samples create another process of themselves from disk binary. In our case, since the original binary in the disk is a hello world, it creates a hello world process and not a malware one.
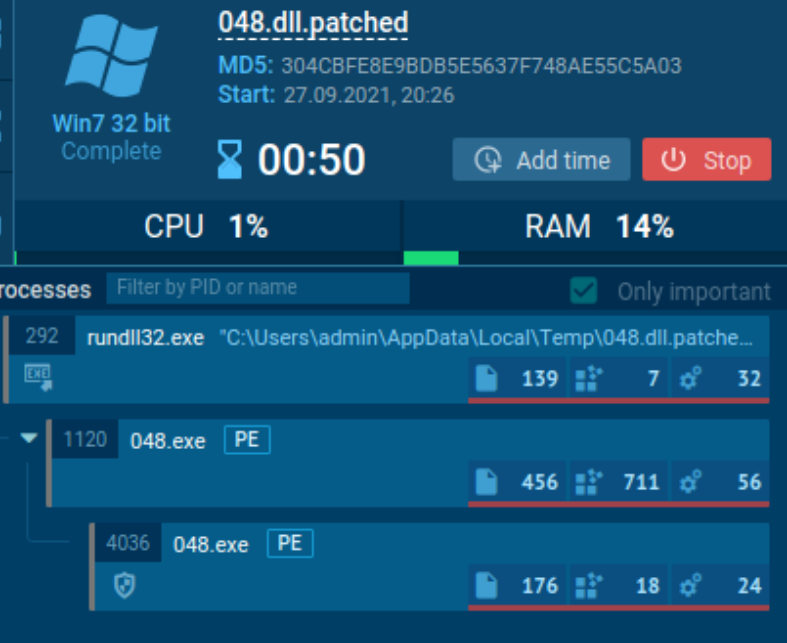
Sample 048 was one of the samples not suitable to be converted to an in-memory payload.
Installers: Some samples provided by the organization are NSIS installers and not traditional PEs. On the one hand, it is bad for our approach, because they cannot be injected regularly as any other installer because their content is not located in PE sections but as blobs of data that are appended to each other. On the other hand, NSIS installers can be extracted and their individual contents handled, including payloads and scripts.
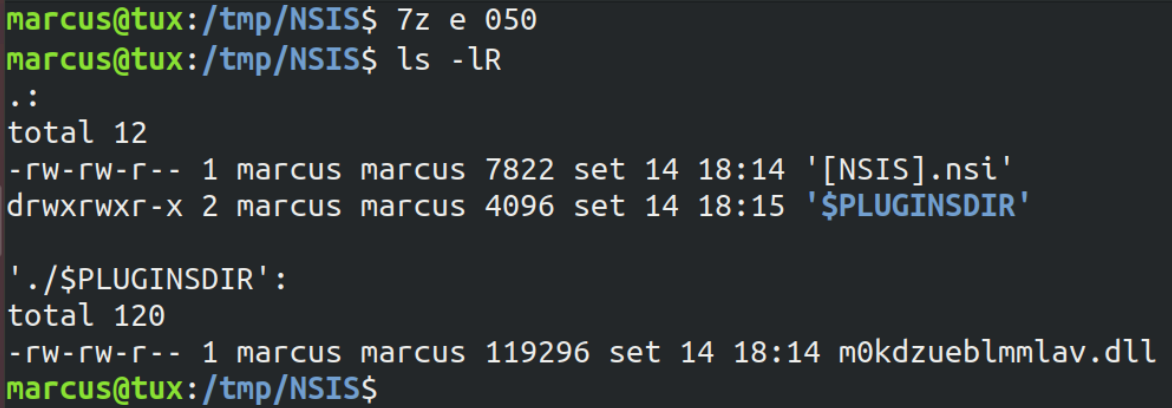
Extracted content from NSIS installer showing a malicious DLL and a loader script.
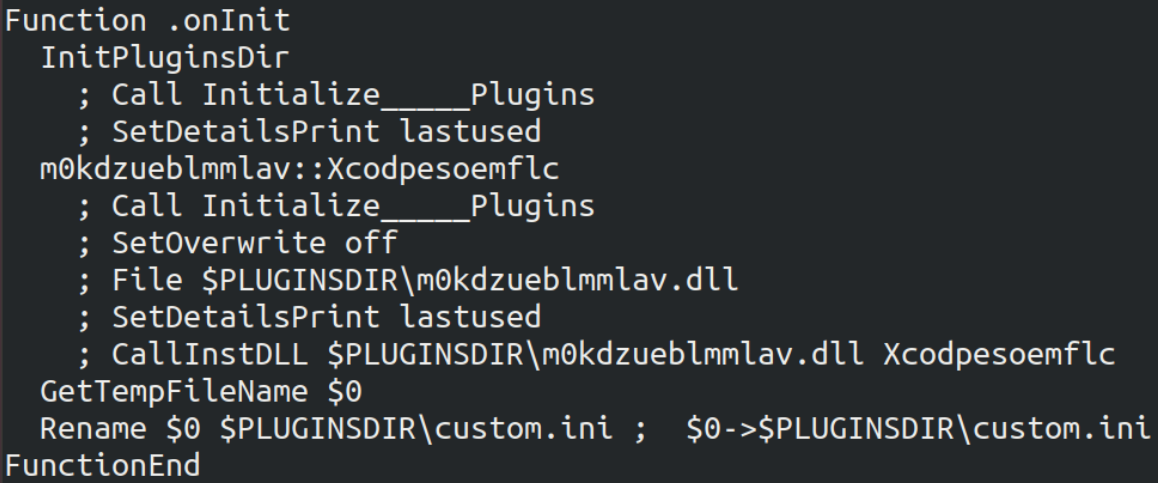
Code excerpt of NSIS script that loads the malicious DLL.
For one of the samples (050), the installer is in fact just a script that loads a DLL, which is actually malicious. The problem is that during the NSIS script operation, it naturally drops the DLL to the filesystem and this DLL is detected by our classifier even though the modified installer would not be. Therefore, the own sample provided by the organization somehow violates the imposed rules that no payload should be dropped to the filesystem, at least in the sense of simulating a real-world operation (it’s fine for competition purposes).
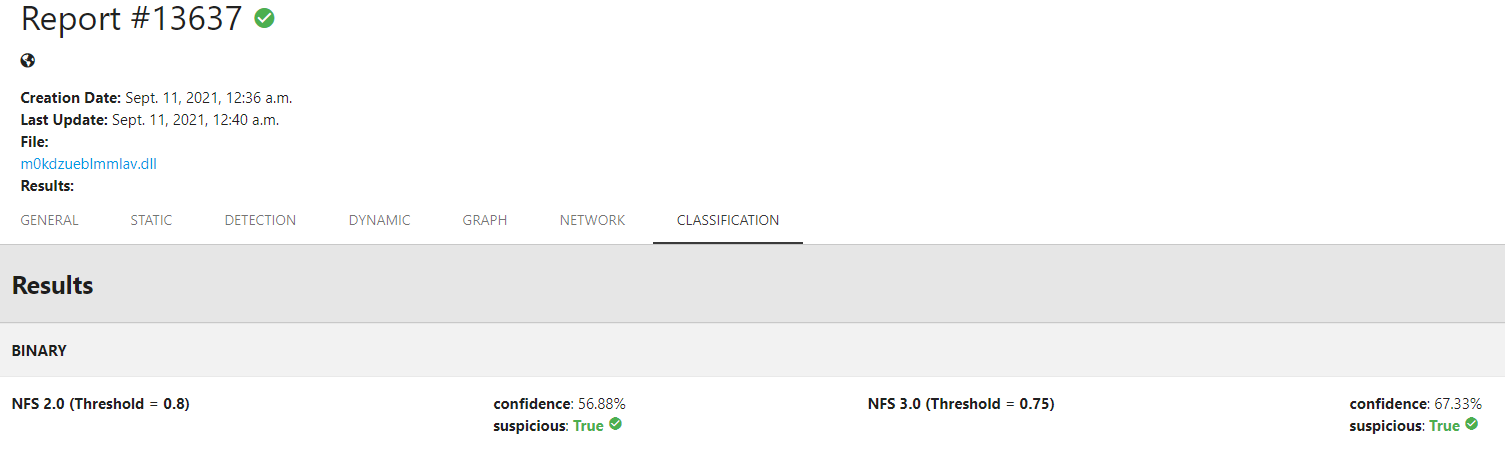
DLL dropped by the NSIS installer is detected by our classifier (report available here).
Minor Tweaks: After we had a dropper, we tried to increase our chance of making it to be classified as goodware by faking some PE header fields, such as timestamps and version fields. It has been proved very effective, especially for bypassing our own classifier. Faking those fields significantly increased the classifier confidence in the result. It seems our classifier started really “believing” the dropper files were the ntdll.dll!
Low-hanging fruits: All the strategy above described was enough to bypass more than 50% of all samples. We didn’t have enough time to handle the corner cases, so we adopted a low-hanging fruit approach, by applying to them the well-known strategies which we attempted in the last years, such as appending random bytes to the binaries and/or trying to repack them. Appending random bytes was successful many times against the “model2_thresh90” model, which seems to be a raw bytes-based model. Repacking was particularly successful for bypassing the models when using .Net samples. The netcrypt packer performed very well in this task, whereas the mpress only helped to bypass a single sample/model.
The Challenge Result: Despite the increased difficulty in this year’s challenge, our solutions were still able to bypass the majority of classifiers for the majority of samples. The following table shows the partial contest results so far (we will update it with official results soon). Of note, our strategy required 5x fewer queries than the one employed by the competitor ranked 2nd, which shows it is very efficient. Our overall message is that although pure-ML attacks have been evolving over years, the consolidated malware-focused attacks, such as those typically employed against AVs, are still very effective and efficient. Moreover, there is no reason to believe that this will change in the near future.
| Nickname | Total Best Score per User | Total API Queries |
| secret | 196 | 600 |
| amsqr | 167 | 3004 |
| rwchsfde | 114 | 55701 |
| vftuemab | 113 | 3772 |
| qjykdxju | 97 | 3302 |
| nomnomnom | 86 | 14981 |
| pip | 74 | 534 |
| dtrizna | 68 | 4085 |
| vxcuwzhg | 13 | 108 |
| fysvbqdq | 12 | 773 |
When we consider the results of our model against the distinct classifiers, our analysis is as follows: we consider that the bypass of our own model is our baseline. In this sense, the models “submission 3”, “scanner_only_v1”, and “kipple” behaved exactly as expected, being bypassed by all samples that also bypassed our own model. In the case of the “submission 3” model, it was also bypassed by some of the described low-hanging fruit attempts, being a bit more fragile to simpler attacks, such as repacking. The “model2_thresh90” and “A1” models were also bypassed by most samples but 1 or 2 specific samples. Since all droppers are built from the same source and the only difference among them is the embedded payload, we believe that these models look to the raw bytes embedded in the dropper to make their verdict. However, since most samples bypassed them even though, we believe we could also bypass them for these remaining samples by modifying a little bit how the patterns of raw bytes look like, for instance, by using distinct XOR keys. Unfortunately, we didn’t have time to perform this experiment, so we will wait for their write-ups to confirm our hypothesis.
Implications: A natural implication of the evasion techniques we employ and/or develop for the challenges is that they can be used not only in the challenge and/or ML context but they can be used to evade actual security solutions, such as AVs. In the previous editions, we demonstrated how the resulting samples were less detected by Virustotal’s AV samples. We repeated this evaluation this year and discovered that the average detection rate of the samples dropped from 73.15% (original) to 48.85% (adversarial), as shown in the Figure below. Thus, we conclude once again (as in previous years) that it is still possible to evade not only Machine Learning detectors but also real AVs.
Reproducibility: If one is interested in checking our dropper and injection strategies, all code we used in the challenge to automate the process is available in our GitHub repository.
SECRET solutions to counter in-memory malware
In addition to participating in the challenge, SECRET researchers conduct many malware defense-related research in their daily lives and many of them involve in-memory malware detection. We following point our research works that might be used to detect the evasive samples we created in a real scenario:
- Detecting Self-Modifying-Code (SMC): Malware samples often modify themselves to hide detectors. If they do it at the code page level, they are called SMC malware. Modifying memory pages introduce side effects on code execution on CPUs and these side-effects might be effectively and efficiently used as triggers for analysis procedures. That is exactly what we proposed in this paper: a CPU able to detect when a malware sample modifies its own code pages and attempts to run it!
- Detecting Fileless Malware: Malware that operate solely from memory and does not have a disk counterpart are the next trend in malware attacks and are exactly the kind of malware we created for this challenge. It would be good if we had efficient ways to detect this type of malware if it is going to become mainstream. This way is to add malware detectors to the system’s memory! This is exactly what we propose in this paper. With that, the challenge’s samples would be detected without performance overhead and, in many cases, even before their execution.
If you survived reading this blog post until here, we hope you have enjoyed it!
See you all next year!
About the Authors

Fabrício Ceschin
B.Sc., CS @UFPR, 2016
MSc, CS @UFPR, 2018
PhD, CS @UFPR, 2023




Marcus Botacin
Computer Eng. @UNICAMP, 2015
MSc, CS @UNICAMP, 2017